

NetApp MetroCluster集群容灾方案
作者:佚名 文章来源:销售部 点击数: 更新时间:2014-08-25 15:32:27
容灾级别介绍
随着信息技术的不断发展,无论是企业还是个人对数据的安全性都非常重视,但任然有相当多的企业或个人缺乏有效的数据安全保护措施,以至于面对频繁的文件丢失、病毒感染、硬盘损坏等风险。现今社会,数据是一个企业的核心,数据的丢失轻则导致财产大量损失,重则导致企业破产、倒闭。因此建立安全、有效的数据容灾对每个企业显得十分重要。
容灾级别分类如下:
级别0 – 没有异地数据 (No off-site Data)
级别0被定义为没有信息存储需求、没有建立备份硬件平台的需求,也没有发展应急计划的需求。数据仅在本地进行备份恢复,没有数据送往异地。这种方式是最低成本的灾难恢复解决方案。事实上这种灾难恢复并没有真正灾难恢复的能力,因为它的数据并没有送往远离本地的地方,而数据的恢复也是利用的本地的记录。
级别1 – 卡车运送访问方式 (Pickup Truck Access Method)
级别1的灾难恢复方案必须设计一个应急方案,能够备份所需要的信息并将它存储在异地,然后根据恢复的具体需求,有选择地建立备份平台,但不提供数据处理的硬件。
级别1是一种被许多数据中心采用的备份标准方式,数据在完成写操作后,将会被送到远离本地的地方,同时准备有数据恢复的程序。在灾难发生后,一整套安装需要在一台未开启的计算机上重新完成,系统和数据可以被恢复并重新与网络相连。这种灾难恢复方案相对来说成本较低(仅仅需要传输工具的消耗以及存储设备的消耗)。但同时有这样的问题,那就是难于管理,即很难知道什么样的数据在什么样的地方。
级别2 – PTAM卡车运送访问方式+热备份中心 (PTAM + Hot Site)
级别2相当于级别1再加上热备份中心能力的进一步的灾难恢复。热备份中心拥有足够的硬件和网络设备去支持关键应用的安装需求。对于十分关键的应用,它必须在灾难发生的同时,在异地有正运行着的硬件提供支持。这种灾难恢复的方式依赖于PTAM方法去将日常数据放入仓库,当灾难发生的时候,数据再被移动到一个热备份中心。虽然移动数据到一个热备份中心增加了成本,但却明显降低了灾难恢复时间。
级别3 – 电子链接 (Electronic Vaulting)
级别3是在级别2的基础上用电子链路取代了卡车进行数据的传送的进一步的灾难恢复。接收方的硬件必须与主站点物理地分离,在灾难发生后,存储的数据用于灾难恢复,由于热备份中心要保持持续运行,增加了成本,但消除了传输工具的需要,提高了灾难恢复速度。
级别4 – 活动状态的备份中心 (Active Secondary Site)
级别4的灾难恢复具有两个中心同时处于活动状态并管理彼此的备份数据,允许备份行动在任何一个方向发生,接收方硬件必须保证与另一方平台物理地分离。在这种情况下,工作负载可能在两个中心之间分享,中心1成为中心2的备份,反之亦然。在两个中心之间,彼此的关键在线数据的拷贝不停地相互传送着。在灾难发生时,需要的关键数据通过网络可迅速恢复,通过切换网络,关键应用的恢复可降低到小时级或分钟级。
级别5– 两中心两段提交 (Two-Site Two-Phase Commit)
级别5在级别4的基础上管理着被选择的数据(根据单一提交的范围在本地和远程数据库中同时更新数据),也就是说在更新请求被认为是成功完成之前,级别5需要生产中心与备份中心的数据都被更新。我们可以想象这样一种情景:数据在两个中心之间相互映像,由远程两段提交来同步。级别5为关键应用使用了双重在线存储,在灾难发生时,仅传送中的数据被丢失,恢复时间被降低到分钟级。
级别6 – 零数据丢失 (Zero Data Loss)
级别6可以实现零数据丢失率,同时保证数据立即自动地被传输到恢复中心。级别6被认为是灾难恢复的最高的级别,在本地和远程的所有数据被更新的同时,利用了双重在线存储和完全的网络切换能力。级别6是灾难恢复中最昂贵的方式,但也是速度最快的恢复方式。
级别7 – 零数据丢失,自动系统故障切换
级别7和级别6实现之间的区别是:当一个工作中心发生灾难时,级别7能够提供一定程度的跨站点动态负载平衡和自动系统故障切换功能。
技术原理
NetApp MetroCluster 是集成的高可用性和业务连续性解决方案,它充分利用来自 NetApp 及其合作伙伴的经过验证的技术。它扩展了 Network Appliance™的全面的高可用性和灾难恢复解决方案套件(这一套件包括故障切换、数据复制和备份解决方案)的功能。MetroCluster 是一种管理简单的解决方案,它将故障切换功能从数据中心内扩展到距离遥远的站点。它还将数据从主站点复制到远程站点,以确保数据是全新的。通过将故障切换和数据复制能力相结合,可以确保用户在几分钟之内(而不是几小时或几天)就可以从灾难中恢复过来,而不会损失任何数据。通过 MetroCluster 所固有的简易性,用户可以迅速切换到远程站点并继续操作,同时将工作重心转回到关键业务决策上。
NetApp的MetroCluster功能,可以在本地实现针对整个数据中心机房发生灾难时包括控制器和数据的自动切换。
1) 只需管理1套存储容灾系统;
2) 对于服务器上的群集软件是透明不可见的;
3) 一旦存储系统发生故障,会在2个控制器以及不同的数据镜像磁盘组之间进行自动切换,完全不会影响应用系统;
4) 故障设备修复后,自动进行数据重同步,恢复原来故障前的运行模式。
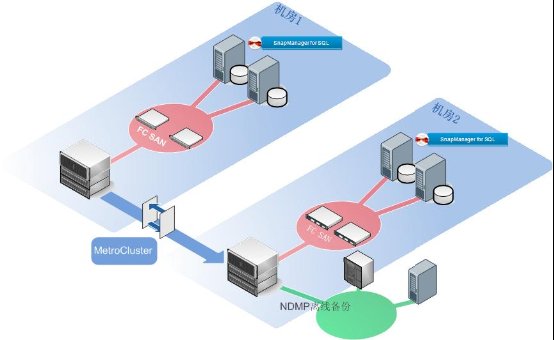
图1核心存储系统结构图
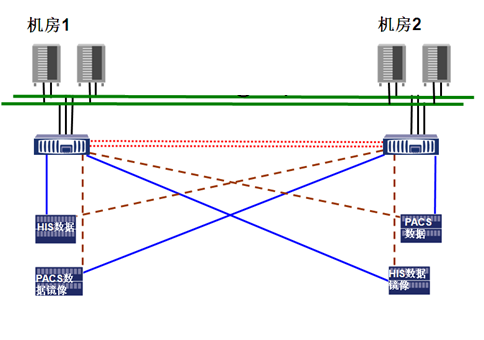
图2数据分布示意图
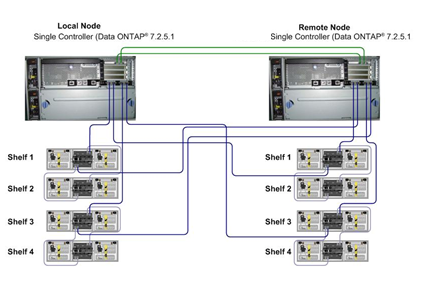
图3近距离的光纤直连架构
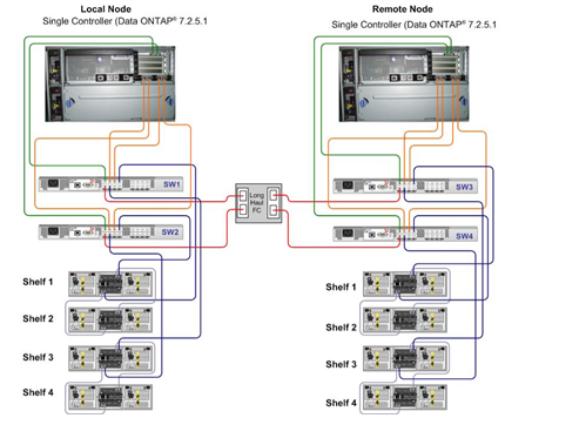
图4远距离的光纤交换机连接架构
MetroCluster冗余链路连接拓扑图
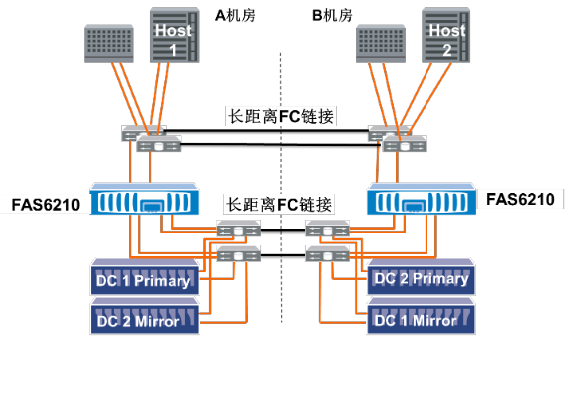
图5 MetroCluster的冗余链路连接拓扑图
如图5所示,NetApp MetroCluster的硬件配置有严格的冗余链路要求。
首先,要求主机/服务器端至存储控制器之间必须为双链路确保链路冗余配置,在8Gb FC条件下,如果两端距离超过280米,必须使用光纤交换机配置长距离SFP模块,以保证长距离的两端的光纤网络的双路通讯畅通;这样做,目的是为了在主机和服务器上对存储控制器足够的冗余链路访问;
其次,MetroCluster的硬件配置,在存储内部也必须配置4个光纤交换机,同样地,在8Gb FC条件下,如果两端距离超过280米,必须使用光纤交换机配置长距离SFP模块,以保证长距离的两端的光纤网络的双路通讯畅通;
第三,MetroCluster环境下,存储控制器和磁盘柜之间通过4套内部交换机实现交叉互联;
第四,MetroCluster通过其SyncMirror功能,每个控制器都同时向主端的磁盘柜上的LUN/卷、以及容灾端的磁盘柜上的LUN/卷进行同时镜像写入;
第五,NetApp MetroCluster通过控制器冗余和冗余链路,使得服务器/主机共有4个PV链路访问;其中2个链路可以访问主端的LUN/卷,2个链路访问容灾端的镜像LUN/镜像卷。
如此,NetApp MetroCluster用高可用的冗余链路简单方式,实现任何一个节点上的硬件故障,都可以让应用通过第二个链路进行持续的数据访问,从而避免了手工或者脚本控制的故障切换操作,大大简化了容灾系统的架构设计、管理需求,使得用户避免在容灾切换过程中出现二次失误,极大地保障了容灾系统的实用、高效、简单。
MetroCluster的镜像写入方式
由于存储控制器和磁盘柜之间存在8Gb的高速FC链路,MetroCluster软件使用其SyncMirror功能,实现控制器对本地磁盘柜中的源数据LUN和远程磁盘柜中的镜像LUN的同步镜像写入。在正常工作状态下,应用层的主机或者服务器,只需将数据通过Primary PV链路写入相对应的NetApp存储控制器即可,镜像工作由控制器完成。如图6所示:
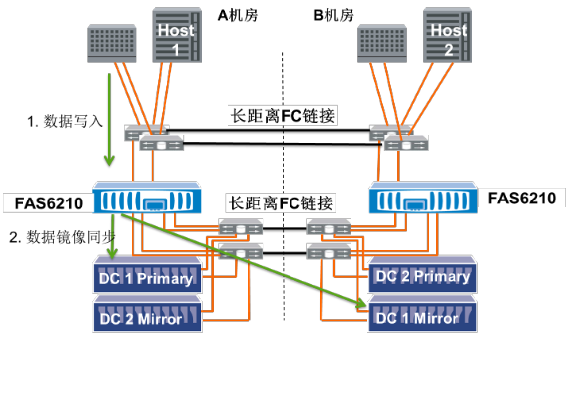
图6 MetroCluster正常状态下的数据镜像写入
当主中心存储控制器故障时,服务器/主机操作系统自动选择容灾端控制器写入主中心端磁盘柜;当修复后,系统可以随时接管到主中心控制器。见图7所示:
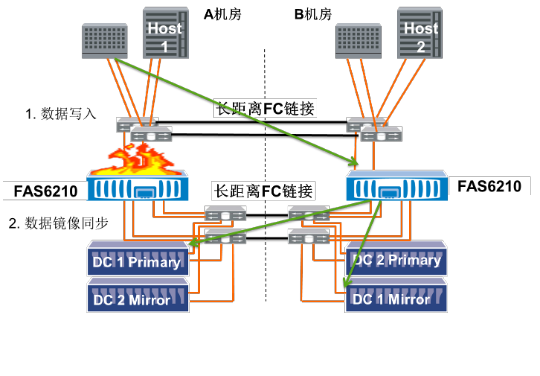
图7当主中心存储控制器故障时,MetroCluster数据的镜像写入
当主中心磁盘柜故障时,主中心端控制器写入容灾端镜像磁盘柜;不影响生产数据写入;当修复后,存储利用SyncMirror功能自动同步差异数据。
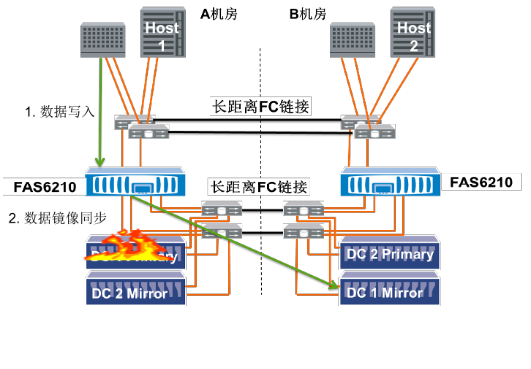
图8当主中心磁盘柜故障时,MetroCluster数据的写入
当主中心存储整体故障时,服务器/主机操作系统自动选择容灾端控制器写入容灾端磁盘柜;当修复后,系统可以随时接管到主中心控制器,存储利用SyncMirror功能自动同步差异数据。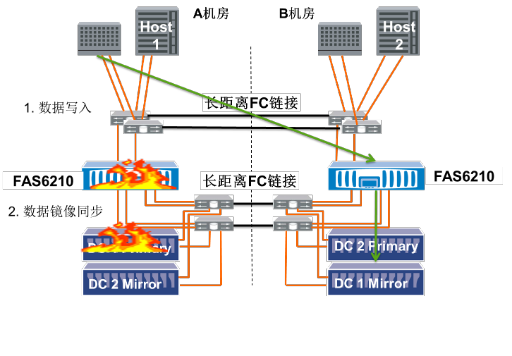
图9当主中心存储整体故障时,MetroCluster数据的写入
在容灾链路故障时,控制器继续写入本地,不影响生产数据写入性能;当容灾链路恢复时,存储利用SyncMirror功能自动同步差异数据。
MetroCluster的自动化灾难/故障切换
其他友商的数据容灾方案中一定存在复杂灾难/故障切换流程,如:
步骤1 分离镜像对(挂起或删除镜像对)
步骤2 切换主机系统到备份中心
步骤3 ONLINE RVOLs 激活RVOLs,使备份中心RVOLs可读写
步骤4 在恢复模式下启动数据库
步骤5 利用数据库日志文件恢复数据库(Redo、Rollback)
步骤6 切换数据库至“打开”模式
步骤7 启动用户应用
步骤8 同时,用户IP网络进行相应的切换处理
有的方案利用额外的软件定制这些步骤的自动化执行,或者通过脚本进行自动化执行,但是这些步骤依然不能消除,RTO、RPO依然受到制约和影响。
然而,NetApp MetroCluster硬件配置在控制器、磁盘柜之间增加内置光纤交换链路,实现控制器和任意一个磁盘柜之间双路冗余连接,在配置的MetroCluster软件管理下,当存储的任何一个部件发生故障时,或者生产中心发展灾难时,由于服务器/主机访问数据的链路冗余实现了“预配置”,应用系统的服务器或者主机将通过冗余链路通过第二条链路访问数据,实现容灾或者故障时的自动化切换,从而无需任何人工命令或者脚本控制切换,且对前端应用不产生任何影响。
MetroCluster灾难恢复简单易操作,回切操作简单
由于NetApp MetroCluster 硬件架构利用双物理链路、4个逻辑链路访问数据的,故障/灾难后,所有修复均为硬件更换,由于服务器/主机访问数据的链路冗余实现了“预配置”,从而在硬件修复工作完成以后,MetroCluster系统自动同步生产中心和容灾中心的差异数据,大大简化了灾难恢复工作的复杂度、降低了容灾恢复的“二次失误”的风险,简化了修复步骤和操作内容,步骤少、易操作。只有在存储控制器出现故障的一种情况下,客户在确认了数据同步完成后,可以一条命令确认即可将IO回切到主中心继续运行。其他情况下不需要任何人工干预。
MetroCluster的容灾系统扩展简单
客户只要在镜像的磁盘柜/组上创建LUN或者卷空间,MetroCluster系统将自动地为新加的LUN或者卷进行存储空间的自动化镜像,借助架构中自有的双物理链路,4逻辑链路设计,实现新应用容灾的完全存储空间镜像操作,无需额外脚本或者软件支持和调整。
对于不需要进行容灾保护的应用,客户只要选择在不在MetroCluster的镜像内的磁盘柜/组上创建LUN或者卷空间即可。
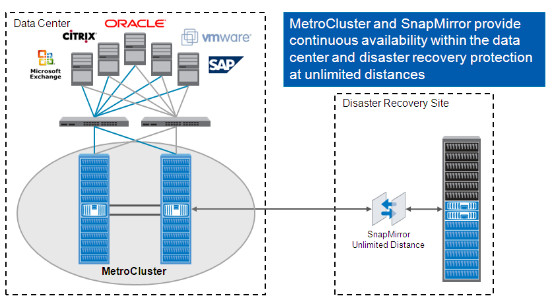
图10将来的存储系统容灾扩展
方案特点
NetAPP FAS系列存储设备5个9的高可用性为业务数据提供了安全、可靠的存储空间,由冗余光纤交换机组成的SAN交换网络为业务数据的高速交换提供可靠保证。
NETAPP FAS系列存储设备内置的本地数据保护软件(如数据快照、本地数据持续保护等)和远程数据保护软件(如数据同步/异步复制技术、远程数据持续保护等)为应用系统数据提供完善的数据保护能力和快速的数据恢复能力,确保业务数据的安全性。
MetroCluster高可用性集群实现双活数据中心,确保数据零丢失以及应用系统的可持续性运行。
敏捷
NETAPP FAS系列存储设备将所有存储资源统一放入存储资源池,同服务器资源池功能类似,可以做到对存储资源池的动态调整和按需分配。
MetroCluster实现存储层任何部件故障的快速切换,切换不影响应用系统内共。
NETAPP FAS系列存储设备的自动数据分层特性,在确保应用系统数据读写性能的前提下,通过不同类型存储驱动器的合理搭配,大大缩减了存储设备的总体投资成本。
NETAPP FAS系列存储设备的虚拟资源调配特性,有效提高了存储空间资源的利用率,并降低了存储设备规划、部署和维护的工作量,提升了管理效率。
- 地址:温州市车站大道大诚商厦E幢四楼 | 电话:0577-88891333 | 技术服务电话:4008515159 | 传真:0577-88363999
- 邮箱:jucher@jucher.com | 浙ICP备05000620号-1
- Copyright © 2009-2019 JUCHER CORPORATION CO., LTD All Rights Reserve